
Using
ALFA NETWORK
ALFA NETWORK
AWUS036NH, AWUS036NEH, AWUS036NF, AWUS051NH v2, AWUS052NH
on OSX 10.11 El Capitan
Supported Model
|
Indoor
|
Outdoor
|
|
– AWUS036NH
– AWUS036NEH
– AWUS036NEF
– AWUS036NF
– AWUS051NH v2
– AWUS052NH
– AWUS052NHS
|
– Tube-UN
– UBDo-nt series
– UBDo-25t
|
(Note: The manufacturer of the chipset used inside these products has not released a driver for the latest versions of OSX, so we are unable to offer official support. We are sharing a workaround here. Sorry for the inconvenience and thank you for your understanding.)
Please follow the below steps in order
1. Change the Security policy to allow installation of third party driver utility
l Open System Preferences and click on “Security & Privacy”
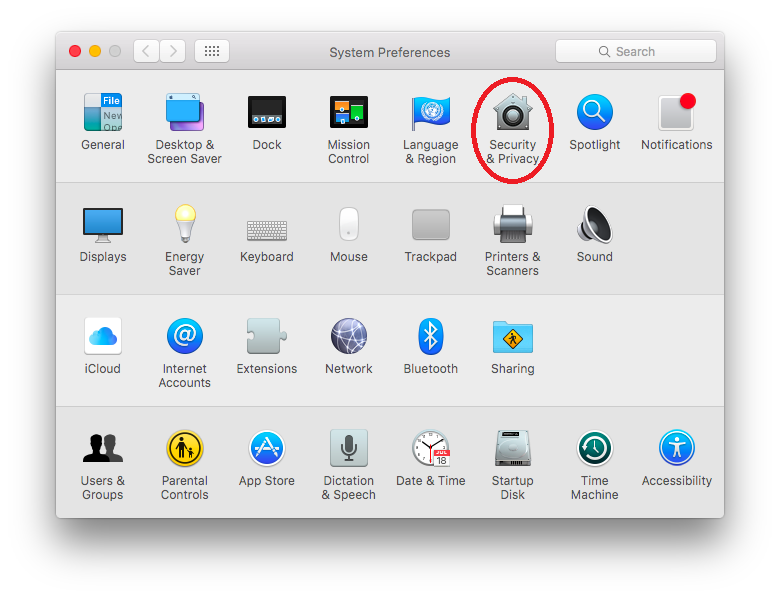
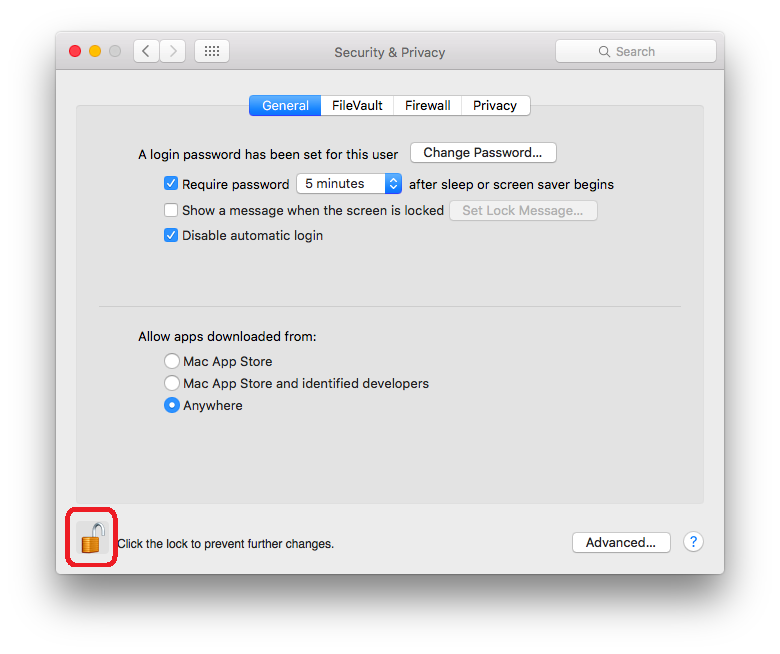
l Click the lock icon to allow changes security settings
l Select “Anywhere” under “Allow apps downloaded from”
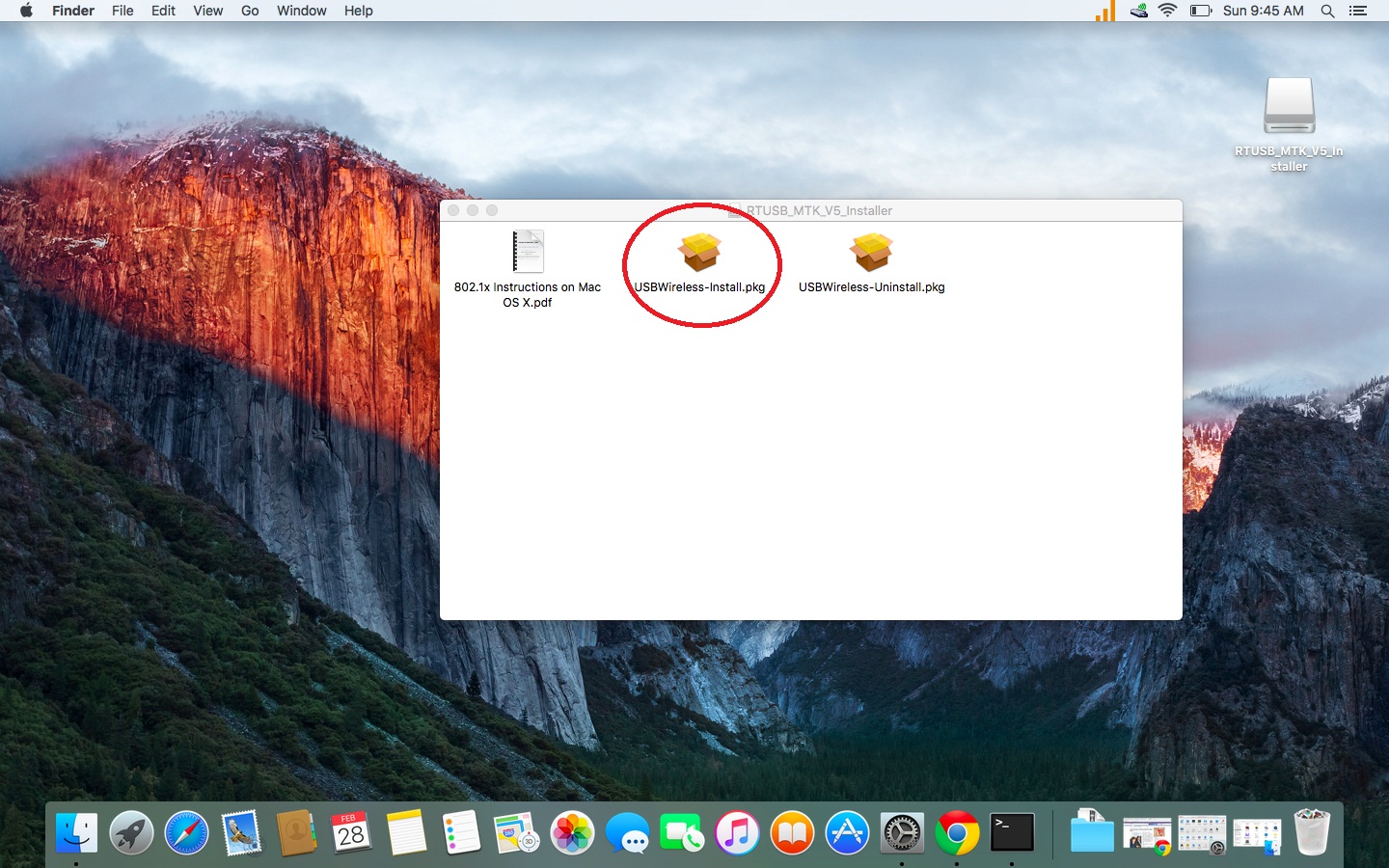
2. Download the file MT Driver_1.0.2.18.dmg <http://download.mtdriver_1.0.2.18.dmg>and install as normal by running the app called: USBWireless-Install.pkg
(You will be asked to reboot your Mac at this time. Please do so before continuing.)
3. Because USBWireless-Install.pkg does not install a required kext file, we have to intall this file manually.
Download the file: RT2870USBWirelessDriver.kext
Download the file: RT2870USBWirelessDriver.kext
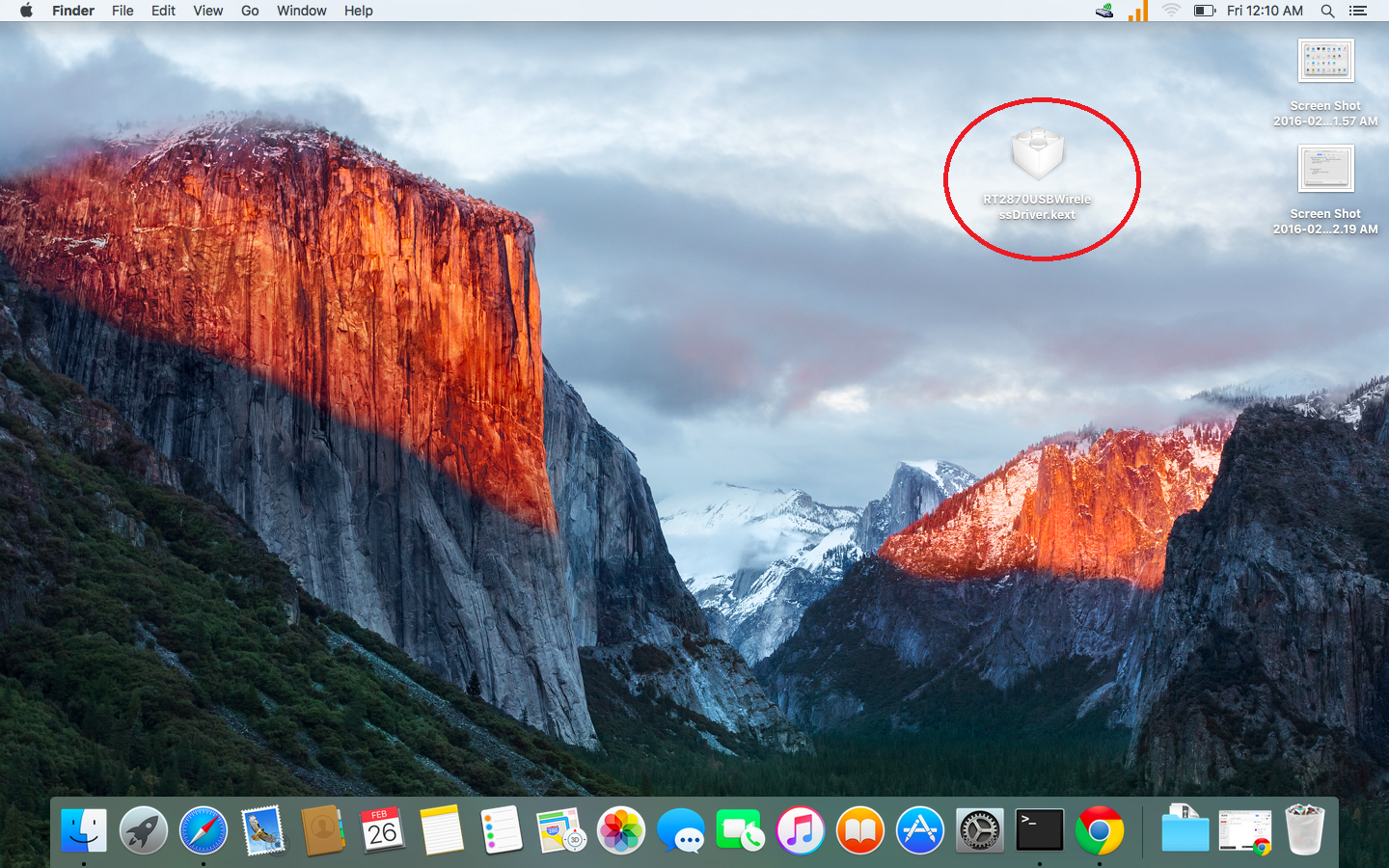
4. Copy RT2870USBWirelessDriver.kext into the folder “/System/Library/Extensions”
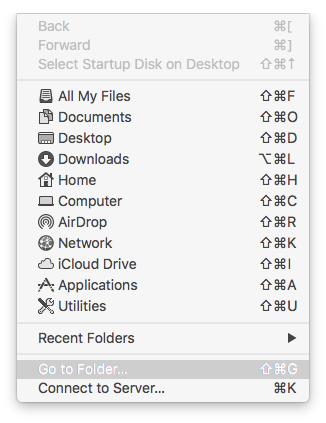
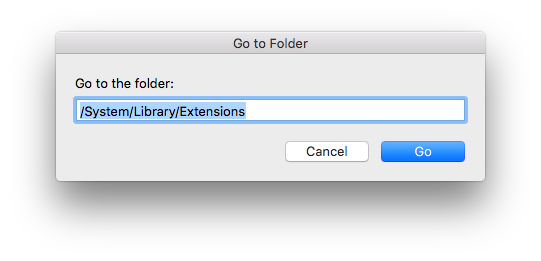
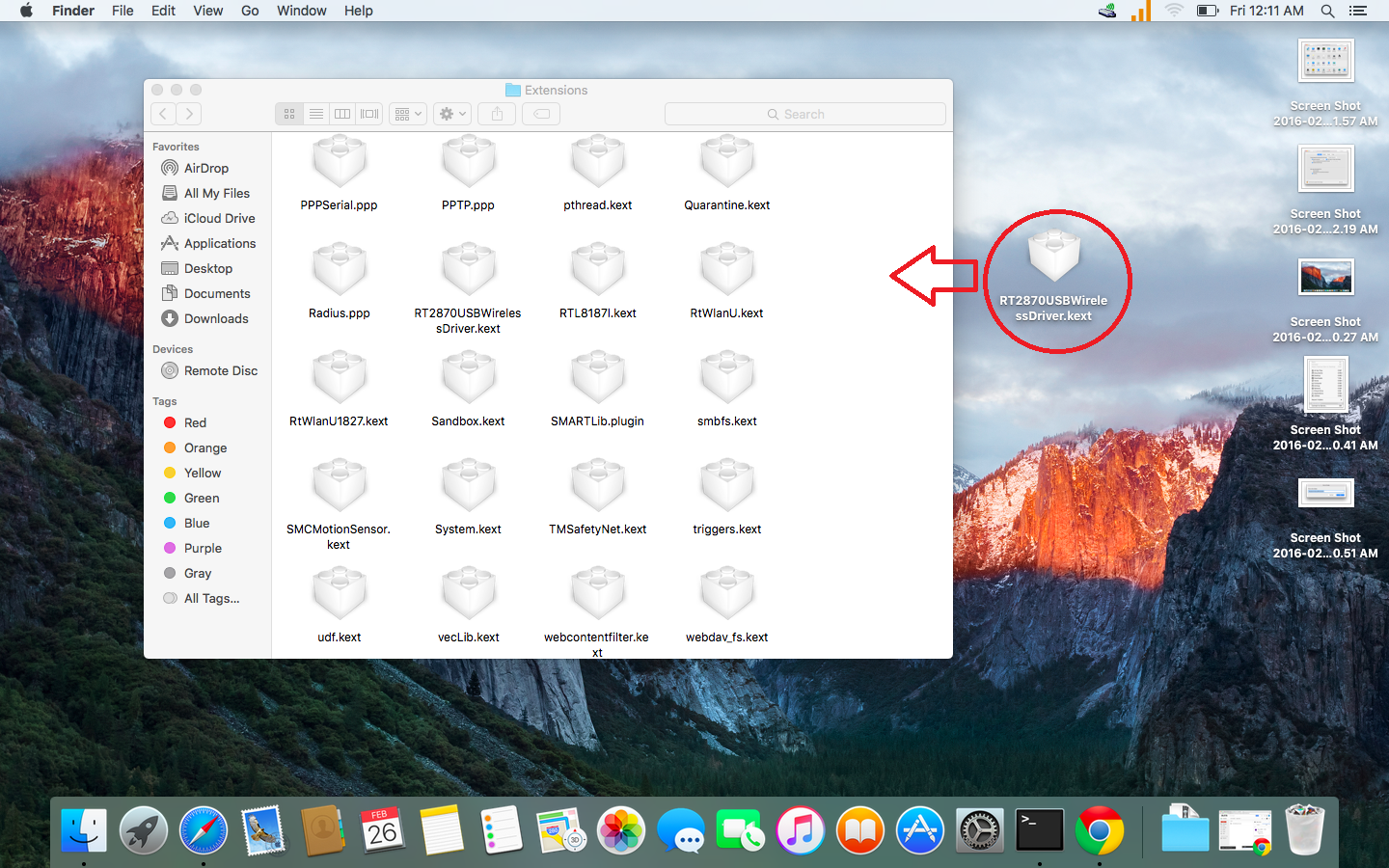
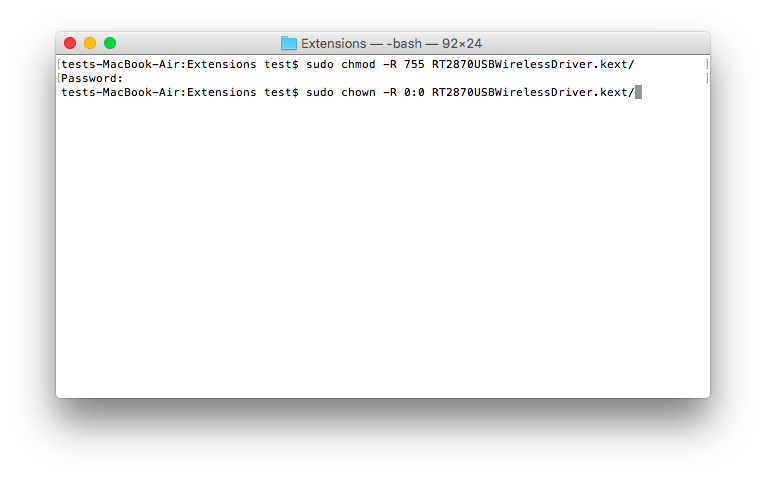
5. Open Terminal and type ( or copy and paste) those 3 commands:
cd /System/Library/Extensions ( enter)
sudo chmod -R 755 RT2870USBWirelessDriver.kext (enter)
sudo chown -R 0:0 RT2870USBWirelessDriver.kext (enter)
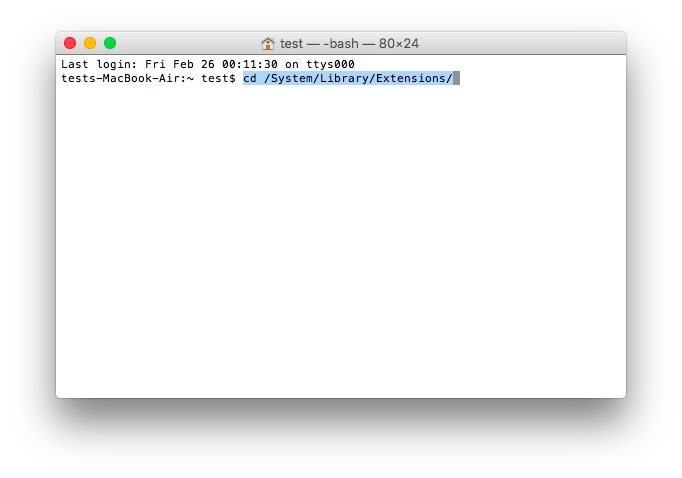
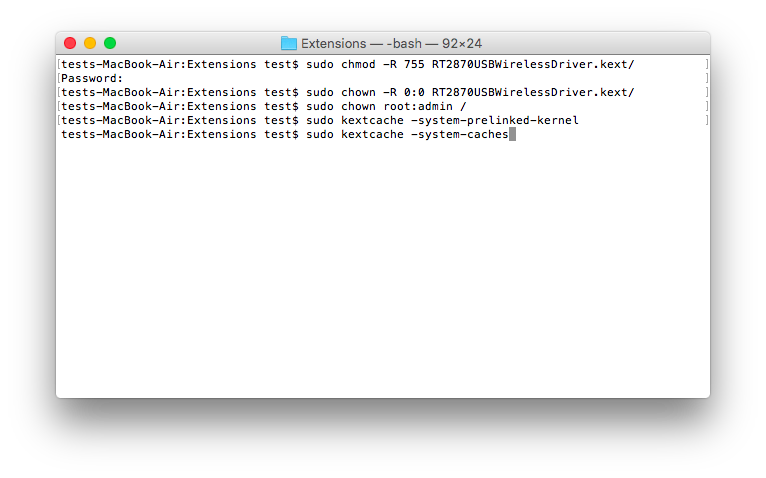
6. Clear the kext cache by typing the following 3 commands in Terminal:
sudo chown root:admin / (enter)
sudo kextcache -system-prelinked-kernel (enter)
sudo kextcache -system-caches (enter)
7. Reboot your Mac and your ALFA wireless adapter should be ready to use
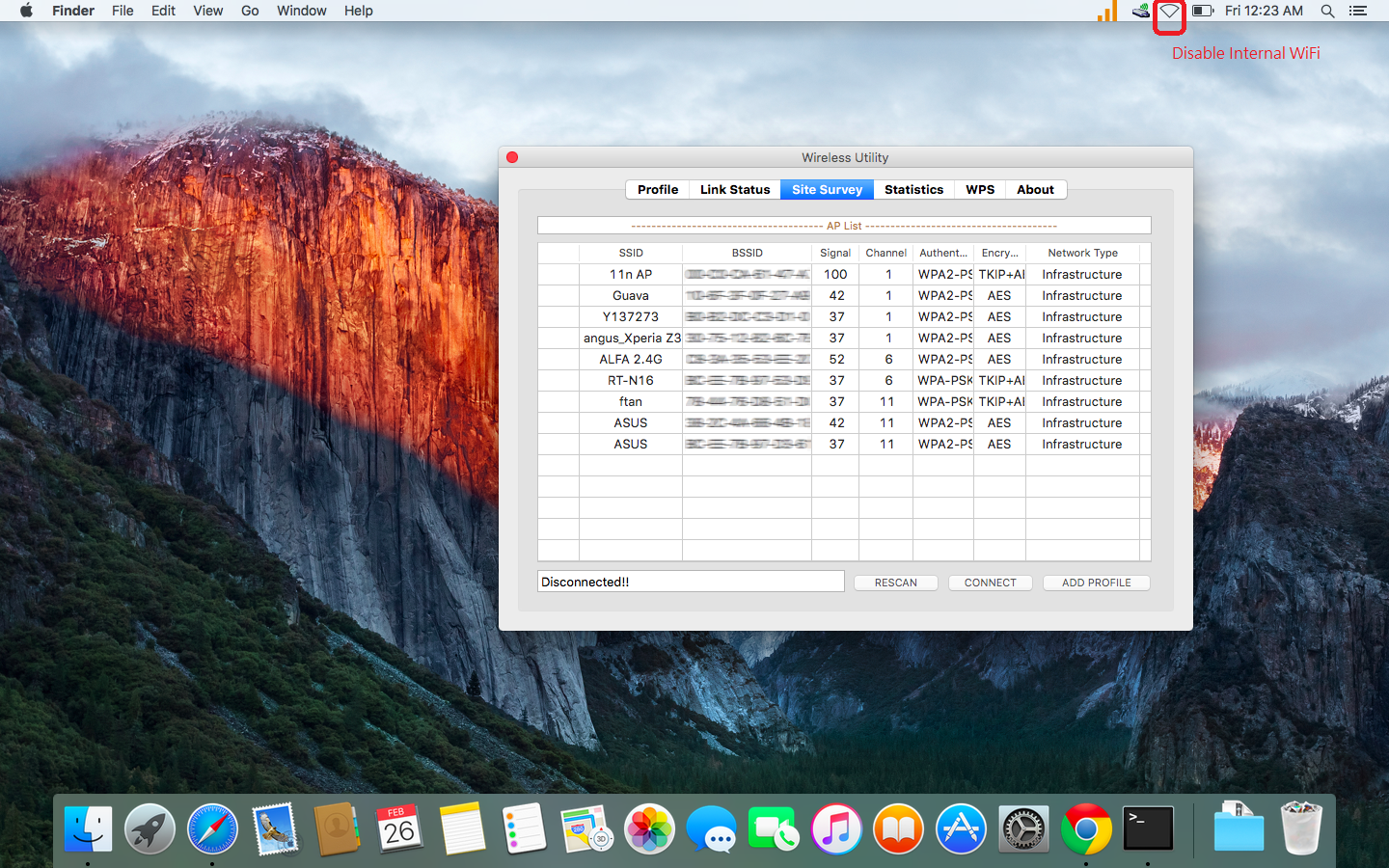
Note: make sure to disable Mac internal WiFi card, in order to work properly

This just bypasses the SIP protection in El Capitan…. Not a good idea. FAIL
LikeLike
I managed finally to install AWUS036NHV on El Capitan. It can scan and see networks. Thanks! But it cannot connect at all and the device looks unplugged from Network Preferences. Help appreciated.
LikeLike
Sorry. Fail again. After the first install the message is always No Wireless NIC Plug in. This on an old mac book air. The same message appears on the super new MacBook Pro of my partner. Sorry for Alfa! I'm about to send back the antenna.
LikeLike
This comment has been removed by the author.
LikeLike
MacBook Pro 15 OS X El Capitan Railink rt2870, rt3070 works.After 3 days of search and the rt3070 installations works in my mac,the detailed instruction was taken from the site http://www.tonymacx86.com/network/183175-guide-installation-usb-wireless-antenna-chipset-rt2870-rt3070-mac-os-x-10-11-x-el-capitan.htmlInstallation of USB Wireless Antenna (chipsets RT2870 or RT3070) using the software \”BearExtender 5.4\”.- OS X 10.11.x (El Capitan)Installation (software)1) Remove workaround first – RESTART2) Remove old files – RESTART3) Install 5.4 (BearExtender) – DONT RESTART YET!4) Connect the USB Wireless AntennaInstallation (driver)5) Run EasyKext Utility6) Drag RT2870USBWirelessDriver.kext to it – RESTARTDeactivation of the SIP (System Integrity Protection) Kext Signing Protection7) Restart your Mac on Recovery Mode- Restart and hold “Command” + “R”8) Open “Terminal”- At “Utilities” menu9) Type “csrutil – -without kext”10) A success message should appear:- “Successfully enable System Integrity Protection. Please restart the machine for the changes to take effect.”10b) An error message may appear (it’s OK)- “csrutil: requesting an unsupported configuration. This is likely to break in the future and leave your machine in a unknown state.”11) If the message on item 10 appears you may RESTART you MacYour USB Wireless Antenna is now working in your mac with “El Capitan”!Enjoy!link for files(BearExtender-5.4, KCPM Utility Pro,RT2870USBWirelessDriver.kext) http://my-files.ru/vwvpt8
LikeLike
There has to be a better way, this is nuts.
LikeLike
Apple introduced SIP(System Integrity Protection) in WWDC 2015, and made a number of security changes to prevent certain malware activities. SIP prevents some low-level activities to system, and drivers of wireless adapters need to be \”injected / mounted\” in system level, The SIP behavior causes driver loading failure in El Capitan, this is also what we're discussing here, where our pain comes from. Disabling SIP to allow drivers to be applied in El Capitan can be the solution for now, thanks to the SIP utility by cvad, the complexity of command-typing is greatly reduced. Carefully refer to the content in this blog, there is great chance to make the wireless adapter functional on your El Capitan.
LikeLike
Adding a network to \”favorites\” and then \”activating\” worked for my wpa aes encrypted network.
LikeLike
Shouldn't your line 9) “csrutil – -without kext”instead read “csrutil enable – -without kext”?
LikeLike
Do you know if there are any plans by the developer to release an update for the RT3070 chipset that will allow installation on 10.11 without disabling SIP?
LikeLike
I am also curious to know if the developer plans to update the RT3070 chipset WITHOUT disabling the SIP.
LikeLike
New driver schedule is not formally update yet; once the driver is completed, and being approved. The new driver will be announced on ALFA Network website for customers.
LikeLike
Jimmy,Do you know if the drivers are under development? I'm trying to figure out if they are just behind or they are dropping support of the chipset.
LikeLike
Does this work for the AWUS036NHA?
LikeLike
No further info from chipset maker for now. If possible, write down the requirement of the wireless adapter, we might give some suggestions for ALFA product selection.
LikeLike
hi please help me I have UBDo 25t from yesterday i tried all drivers from the CD i am with El capitano I tried also with that one here nothing work
LikeLike
Due to chipset manufacturer used in UBDo-25t has not released a driver for El Capitan, please refer to the steps carefully in this page to make UBDo-25t operational on you Mac computer.
LikeLike
please tell me Jimmy do I need to install some driver before use the topping on this article here? By the way I installed Yosemite and downloaded the drivers for 10.10 still negative result ???? Strange
LikeLike
Jimmy if you do not mind I'll be happy to get a help from you here is my skype: stoyanpenkov12
LikeLike
I receive “Untrusted kexts are not allowed
RT2870USBWirelessDriver.kext has invalid signature; omitting.” What can i do ?
LikeLike